Welcome
How information is created, shared and consumed has changed rapidly in recent decades, in part thanks to new social platforms and technologies on the web. With ever-larger amounts of unstructured and limited labels, organizing and reconciling information from different sources and modalities is a central challenge in machine learning.
This cutting-edge tutorial aims to introduce the multimodal entailment task, which can be useful for detecting semantic alignments when a single modality alone does not suffice for a whole content understanding. Starting with a brief overview of natural language processing, computer vision, structured data and neural graph learning, we lay the foundations for the multimodal sections to follow. We then discuss recent multimodal learning literature covering visual, audio and language streams, and explore case studies focusing on tasks which require fine-grained understanding of visual and linguistic semantics question answering, veracity and hatred classification. Finally, we introduce a new dataset for recognizing multimodal entailment, exploring it in a hands-on collaborative section.
Overall, this tutorial gives an overview of multimodal learning, introduces a multimodal entailment dataset, and encourages future research in the topic.
Venue
The Recognizing Multimodal Entailment tutorial will be held live virtually at ACL-IJCNLP 2021: The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing on August 1st 2021 from 13:00 to 17:00 (UTC).
This and the full list of ACL-IJCNLP 2021 tutorials can be found on the conference's program page, and this tutorial session is held for event attendees on the Underline platform.
Outline
| Section | Subsection | min |
| Introduction
|
The landscape of online content | 5 |
| A case for multimodal entailment inferences | 5 | |
| Natural
Language Processing |
From word embeddings to contextualized representations | 15 |
| Fine-tuning pretrained models on downstream tasks | 5 | |
| The textual entailment problem | 5 | |
| Structured Data
|
Semi-structured and tabular text | 5 |
| Knowledge graphs | 5 | |
| Neural Graph Learning | Leveraging structured signals with Neural Structured Learning | 10 |
| Computer Vision | Foundations of Computer Vision | 20 |
| Break | - | 10 |
| Multimodal Learning
|
Attention Bottlenecks for Multimodal Fusion: state-of-the-art audio-visual classifications | 15 |
| Self-Supervised Multimodal Versatile Networks: visual, audio and language streams | 25 | |
| Case studies: cross-modal fine-grained reasoning | 15 | |
| Break | - | 10 |
| Multimodal entailment
|
Multimodal models for entailment inferences | 20 |
| Multimodal entailment dataset | 10 | |
| Final considerations
|
Closing notes | 5 |
| Q&A | 30 | |
| Total | – | 210 |
Slides
Dataset
Colab notebook for Google Research recognizing-multimodal-entailment dataset.A Tensorflow Keras baseline model authored by Sayak Paul using pre-trained ResNet50V2 and BERT-base encoders is available on this well documented Keras.io page, with the accompanying repository.
Illustrative example
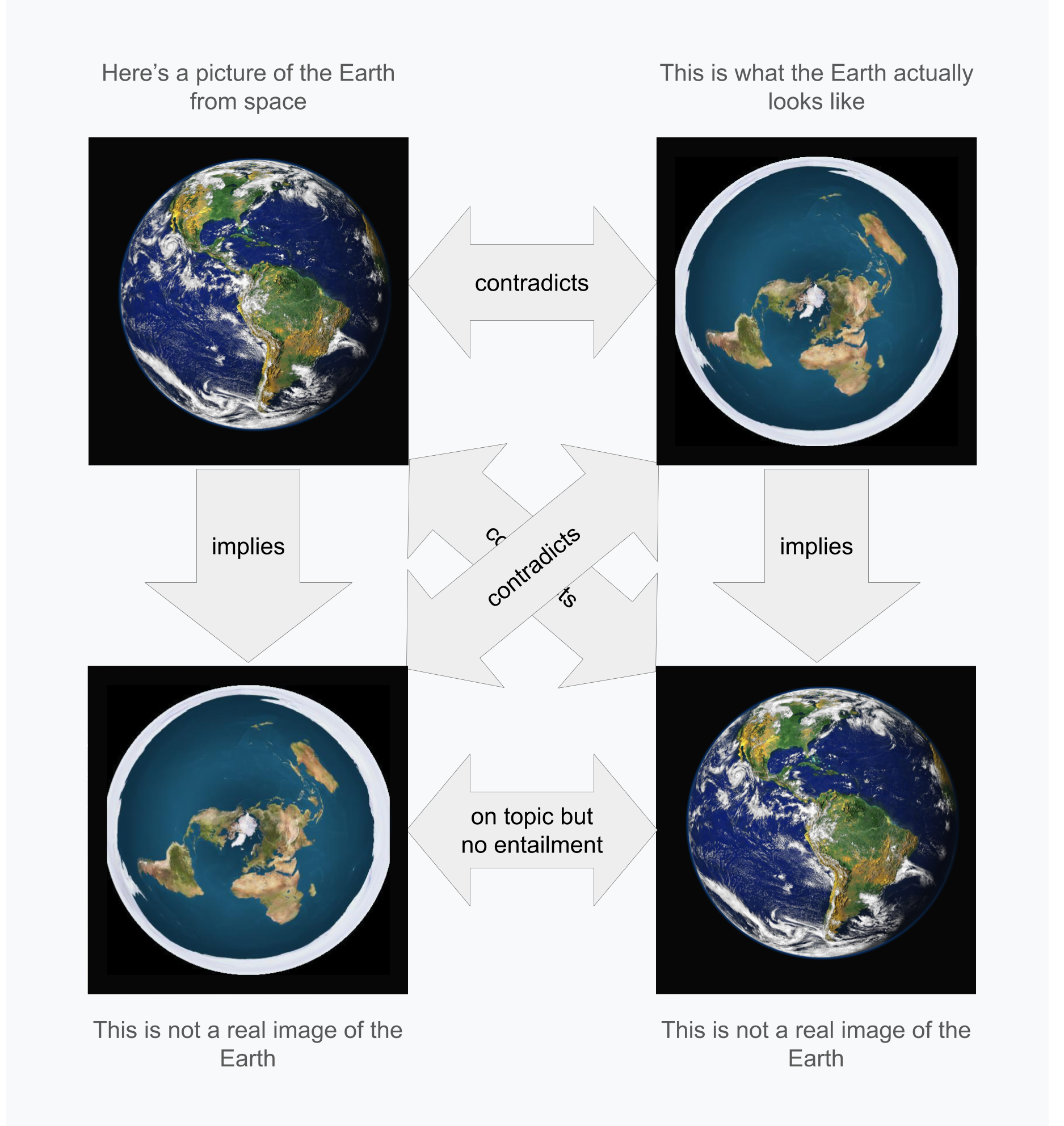
Example of multimodal entailment where texts or images alone would not suffice for semantic understanding or pairwise classifications.
Reading list
Natural Language Processing
- Attention is all you need, Vaswani et at., 2017.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin et at., 2018.
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, Raffel et at., 2019.
- Deep Learning for NLP with Tensorflow, Ilharco et at., 2019.
- High Performance Natural Language Processing, Ilharco et at., 2020.
- Language Models are Few-Shot Learners, Brown et at., 2020.
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding, Lepikhin et at., 2020.
- DeepSpeed: Extreme-scale model training for everyone, Majumder et at., 2020.
Textual Entailment
- The Seventh PASCAL Recognizing Textual Entailment Challenge, Bentivogli et at., 2011.
- Did It Happen? The Pragmatic Complexity of Veridicality Assessment, de Marneffe et at., 2012.
- The Multi-Genre Natural Language Inference (MultiNLI) corpus, Williams et at., 2017.
- XNLI: Evaluating Cross-lingual Sentence Representations, Conneau et at., 2018.
Structured Data
- Industry-scale Knowledge Graphs, Noy et at., 2019.
- Understanding categorical semantic compatibility in KG, Muxagata et at., 2019.
Neural Graph Learning
- Neural Graph Machines: Learning Neural Networks Using Graphs, Bui et at., 2017.
- Neural Structured Learning: Training Neural Networks with Structured Signals, Heydon et at., 2020.
Computer Vision
- Foundations of Computer Vision, Corso et at., 2014.
- CS231n: Detection and Segmentation, Li et at., 2017.
- CS231n: Convolutional Neural Networks for Visual Recognition, Li et at., 2021.
- Rapid Object Detection using a Boosted Cascade of Simple Features, Viola et at., 2001.
- Convolutional Networks for Images, Speech, and Time-Series, LeCun et at., 1998.
- ImageNet Classification with Deep Convolutional Neural Networks, Krizhevsky et at., 2012.
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, Howard et at., 2017.
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, Tan et at., 2020.
- Designing Network Design Spaces, Radosavovic et at., 2020.
- CLIP: Connecting Text and Images, Radford et at., 2021.
- Learning Transferable Visual Models From Natural Language Supervision, Radford et at., 2021.
- A Simple Framework for Contrastive Learning of Visual Representations, Radford et at., 2021.
- Bootstrap your own latent: A new approach to self-supervised Learning, Grill et at., 2020.
- Unsupervised Learning of Visual Features by Contrasting Cluster Assignments, Caron et at., 2021.
Multimodal Learning
- Multimodal Deep Learning, Ngiam et at., 2011.
- DeViSE: A Deep Visual-Semantic Embedding Model, Frome et at., 2013.
- Learning a Text-Video Embedding from Incomplete and Heterogeneous Data, Miech et at., 2018.
- VideoBERT: A Joint Model for Video and Language Representation Learning, Sun et at., 2019.
- HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips, Miech et at., 2019.
- Learning Video Representations using Contrastive Bidirectional Transformer, Sun et at., 2019.
- Use What You Have: Video Retrieval Using Representations From Collaborative Experts, Liu et at., 2019.
- Exploiting Multi-domain Visual Information for Fake News Detection, Qi et at., 2019.
- LXMERT: Learning Cross-Modality Encoder Representations from Transformers, Tan et at., 2019.
- Visual Entailment: A Novel Task for Fine-Grained Image Understanding, Xie et at., 2019.
- Exploring Hate Speech Detection in Multimodal Publications, Gomez et at., 2019.
- VL-BERT: Pre-training of Generic Visual-Linguistic Representations, Su et at., 2020.
- r/Fakeddit: A New Multimodal Benchmark Dataset for Fine-grained Fake News Detection, Nakamura et at., 2020.
- 12-in-1: Multi-Task Vision and Language Representation Learning, Lu et at., 2020.
- SAFE: Similarity-Aware Multi-Modal Fake News Detection, Zhou et at., 2020.
- Multimodal Multi-image Fake News Detection, Giachanou et at., 2020.
- Speech2Action: Cross-modal Supervision for Action Recognition, Nagrani et at., 2020.
- Multimodal Categorization of Crisis Events in Social Media, Abavisani et at., 2020.
- Cross-Modality Relevance for Reasoning on Language and Vision, Zheng et at., 2020.
- Self-Supervised MultiModal Versatile Networks, Alayrac et at., 2020.
- Multi-modal Transformer for Video Retrieval, Gabeur et at., 2020.
- X-LXMERT: Paint, Caption and Answer Questions with Multi-Modal Transformers, Cho et at., 2020.
- The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes, Kiela et at., 2021.
- COSMOS: Catching Out-of-Context Misinformation with Self-Supervised Learning, Aneja et at., 2021.
- VinVL: Revisiting Visual Representations in Vision-Language Models, Zhang et at., 2021.
- ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision, Kim et at., 2021.
- UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning, Li et at., 2021.
- MultiModalQA: Complex Question Answering over Text, Tables and Images, Talmor et at., 2021.
- Attention Bottlenecks for Multimodal Fusion, Nagrani et at., 2021.
Presenters

Afsaneh Shirazi,

Arjun Gopalan,
Google Research

Arsha Nagrani,
Google Research

Cesar Ilharco,

Christina Liu,
Google Research

Gabriel Barcik,
Google Research

Jannis Bulian,
Google Research

Jared Frank,

Lucas Smaira,
DeepMind

Qin Cao,
Google Research

Ricardo Marino,

Roma Patel,
Brown University